Clobber Builds Part 2 - Fixing Missing Dependencies
This is part 2 in the clobber build series. Here we'll look at how to fix the issues stemming from part 1 -- missing dependencies -- once and for all.
Clobber Builds - Recap
In part 1 of the series, we saw how missing dependencies in the Makefile can cause an incremental build to produce a different result from a full build. With two versions of our software, A and B, we expect to always end up at B' in this diagram, but sometimes we don't:
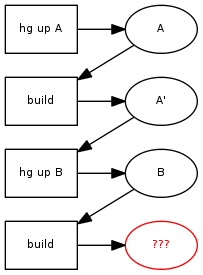
There are two main problems that we covered last time. They are:
- gcc's automated dependency solution (-MMD) doesn't track files that don't exist yet. Creating a file earlier in the include path can cause a clobber build, even with these "perfect" dependencies.
- Only gcc has -MMD. Everything else in the build system must be tracked manually, and people sometimes make mistakes.
Now let's fix these.
Tracking non-existent files with gcc
As we saw in part one, when passing in -I flags to a gcc command-line, only the actual header file is reported as a dependency, whereas the non-existent files earlier in the include path are not. The code that handles this in gcc is pretty straight-forward. Here's a rough outline in pseudocode:
cpp_push_include(filename)
{
foreach include_path
{
if open(include_path + filename)
{
save_dependency(include_path + filename)
return true
}
}
return false
}
If we want to save the dependencies on files that don't exist yet, the fix is pretty easy to do. We just move the save_dependency call before we check the return value of open:
cpp_push_include(filename)
{
foreach include_path
{
save_dependency(include_path + filename)
if open(include_path + filename)
{
return true
}
}
return false
}
Now we would get the correct dependencies, so if we created a header file earlier in the include path, make would know that it needs to recompile. So, why don't I write an actual patch and submit it to gcc? Because it doesn't fix the overall problem.
Only gcc has -MMD
Getting -MMD to work correctly would be great if gcc was the only game in town, but it's not. We still have python scripts, shell scripts, even compiled binaries that are built by make and then also used by make to generate still more files. So let's naively add -MMD support there too!
Python
We'll need a wrapper function to catch all open() calls, so we can save the dependencies...
real_open = open
def dep_open(filename):
save_dependency(filename)
return real_open(filename)
open = dep_open
Shell
We'll need a wrapper function, similar to the one in gcc...
my_open(filename)
{
save_dependency(filename)
return open(filename)
}
Everything Else
Hopefully you can begin to see the pattern - we are doing the same thing over and over again. If we want to apply a fix like the "track non-existent files" patch, we have to fix it in a whole bunch of programs. Or if we want to also track stat() accesses, we have to add that to every program. Relying on each individual program to support an automatic dependency generation model is a bad idea. Instead, the build system should have a way of automatically tracking dependencies for all programs, so it can be done in one place.
What happens when you open()
When a program calls open(), be it gcc, or your own C program, or even your Python script, it ends up calling the open() function defined in libc. Usually this comes from libc.so, unless your program is statically linked. The function in libc is pretty simple - it basically just unpacks the mode argument and does a syscall into the kernel. From there, the kernel figures out what file-system is responsible for opening the file, and calls the file-system's open function. Here's what it looks like:
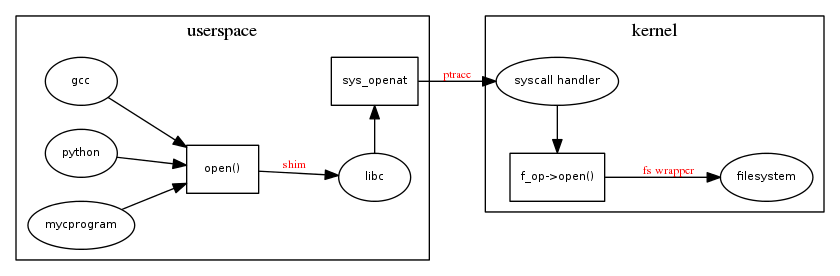
The three links with red text show potential spots where we can watch all of the file accesses of the program. Hooking into one of these areas will allow the build system to support automatic dependency generation for all programs, not just gcc. Let's take a look at each one:
Shared Library Shim
We can stick a shim library in between the program and libc, so that we can watch the open() call as it goes by. In Linux, this is done by using the LD_PRELOAD environment variable (here's an LD_PRELOAD tutorial). In OSX, the environment variable is DYLD_INSERT_LIBRARIES (here's a simple DYLD_INSERT_LIBRARIES example that doesn't require DYLD_FORCE_FLAT_NAMESPACE). There are some pros and cons to this approach:
- pro: Easy to build and prototype.
- pro: All done in userspace.
- con: The actual function names to wrap don't always match what the program is using (due to macros, etc). These function names can also vary among libc versions and platforms.
- con: Symlinks are tricky to support correctly.
- con: Doesn't work with statically-linked binaries on Linux (Apple doesn't support statically linking libc, so it doesn't have this issue).
All in all this approach is quite good, and in fact was the approach that tup used initially. The odd function names can be addressed by adequate test case coverage, and symlinks can be handled internally with some additional logic to find all symlinks referenced by a particular path. However, the fact that statically-linked binaries didn't work at all turned out to be prohibitive. In particular, the binaries for the Go programming language were statically linked on Linux at the time. Additionally, many of the core binaries on FreeBSD systems (including gcc) are statically linked, so the shim wouldn't work for much there at all. Since OSX doesn't have this issue, I am starting to favor it again, but only on that particular platform.
Ptrace
The leap from user-space to kernel-space can be hooked by the build system to watch for system calls. On Linux this is done using the ptrace() function (here's a ptrace example). You are probably more familiar with the command-line strace program, which is built around ptrace(). Ptrace is handy because even a statically linked binary will go through the syscall layer, so it sees everything. Here's how it plays out:
- pro: All done in userspace.
- pro: Works with statically linked binaries.
- con: The syscall layer is platform specific, so Linux is quite different from BSDs, etc.
- con: The syscall layer is machine specific, so x86_64 is different from i386, powerpc, etc. You're dealing with registers here.
- con: The ptrace() function itself is platform specific, so there are different flags and styles of dealing with forked subprocesses.
- con: Pulling strings out of a syscall, like the filename in open(), happens one word at a time. (Some systems like FreeBSD can grab whole strings at a time -- every platform's ptrace() is different!)
- con: All syscalls are intercepted, not just the ones you are interested in.
- con: Symlinks are tricky to support correctly.
Many of these cons can be overcome by abstracting away the implementation details of the various platforms and machines that need to be supported. On Linux, the machine details can be ignored by using the code for strace as a starting point, though unfortunately it does not have a library or well-defined API to use. I am not aware of a cross-platform ptrace() library, but that would certainly be handy!
Performance can also be an issue with ptrace() since all syscalls are intercepted, and pulling out strings requires many syscalls. This is particularly noticeable for small processes, where the overhead can easily double the runtime. While ptrace is not a good all-round solution, this could be used in conjunction with a shared library shim to work around the shim's shortcoming with statically-linked binaries. However, that means building and maintaining two separate tracing libraries.
Filesystem Wrapper
The last place we can hook an open() call is in the file-system itself. Rather than actually implementing this in ext4, btrfs, or any other file-system of the day, we can do something similar to the shared library shim and wrap the file-system. Essentially, we can implement a passthrough file-system that looks like a real file-system with functions like open(), release(), read(), write(), etc. When these functions are called, we can track the file access and then call the real function for the underlying file-system. When the build-system kicks off a sub-process, it will run it in the wrapper file-system instead of the real one.
- pro: Works with statically linked binaries.
- pro: Handles symlinks much more easily.
- con: Either you do this in kernel space (with a new kernel module for the wrapper fs), or you use something like FUSE and pay a performance penalty for going back and forth between kernel/userspace for every read and write call. The performance issues are discussed more in my post about linking libxul with tup and fuse.
In my experience, the filesystem wrapper is a more natural fit for dependency tracking and sandboxing. Handling paths is much simpler - consider if a subprocess does something like open("foo/../bar/baz.txt"). In a shared library shim or with ptrace, we have to:
- Canonicalize the pathname with the current working directory to find out what actual file is referenced.
- Figure out whether any of 'foo', 'bar', or 'baz.txt' are symlinks, and track them (as well as any links they point to).
In comparison, a filesystem wrapper will see this, assuming we have baz.txt as a symlink for real.txt:
- readlink("/home/marf/myproject/bar/baz.txt")
- open("/home/marf/myproject/bar/real.txt")
The code to handle the second case is much simpler to deal with. Tup is currently using FUSE for on Linux and OSX machines, though the performance impact can be frustrating at times. Most of it comes from having all read() and write() calls go through the wrapper filesystem, which is unnecessary for a build system and is a completely solvable problem. However, since I (and everyone else interested in passthrough filesystems) have had trouble getting that upstreamed, I am considering alternative solutions. In particular since OSX doesn't have the statically-linked libc limitation, I think a shared library shim is a good alternative there. If anyone has thoughts on how to handle this better in Linux, please let me know!
Automatically Tracking Dependencies for Everything
Although each of the various methods of global automated dependency tracking has its ups and downs, that's not really the point of this post. The point is that missing dependencies are a can be fixed -- not one at a time whenever someone stumbles across them (our current whack-a-mole approach at Mozilla) -- but forever.
Consider bug 984511 - do you think it was worth bhackett's time trying to debug the cause of test failures, clobbering, rebuilding everything from scratch, and ultimately filing the bug? Is it worth froydnj's time to track it down to a missing dependency, and adding it manually?
And if for some reason you still think that we can solve this by continuing to manually add dependencies, think again. I ran embedjs.py (the command used in bug 984511) in tup without manually specifying all the dependencies. It picked up the TypedObjectConstants.h dependency automatically, which means if we had been using tup as our build system, we would have simply never filed the bug in the first place. It also picked up the dependency on SelfHostingDefines.h, which is a new file introduced last month. Now we have bug 1007343. Time to whack another mole...
comments powered by DisqusAbout
![]() Hello, you've reached Mike Shal's blog. I may have some info on build systems, Linux, and/or life at Mozilla. Hopefully you will find some of it useful!
Hello, you've reached Mike Shal's blog. I may have some info on build systems, Linux, and/or life at Mozilla. Hopefully you will find some of it useful!
Categories
Archive
Links
Quotes
We've been going about this all wrong. I blame myself.
- Sandlot