Linux Namespacing Pitfalls
Linux namespaces are a powerful feature for running processes with various levels of containerization. While working on adding them to the tup build system, I stumbled through some problems along the way. For a rough primer on getting started with user and filesystem namespaces, along with how they're used for dependency detection in tup, read on!
Visualizing the Taskcluster Index
I've been working on trying to organize the Taskcluster index in bug 1133074. The index is analogous to the directory structure that we have on ftp.mozilla.org, but it is much easier to organize things based on how we'd like to access them. In FTP, our upload scripts actually ssh into the ftp server and copy files around into the layout we want. But with Taskcluster indexing, we can just add a new route and now we can organize things by revision, platform, branch, or however we'd like.
However, the sheer amount of things we build still makes this tricky. I pulled down the build logs for all the mozilla-central builds I could find, and ended up with 106 builds from buildbot/mozharness (including nightlies and l10n), and 16 builds from Taskcluster. That's a lot of routes to get organized into a usable hierarchy!
Try not. Do, or do not.
Despite the existence of hg.mozilla.org/try, I sometimes feel that "there is no try", or at least not a try that I would like. My concern for this post covers three main areas: how the input to try is specified, how the output (failure or success) is determined, and how long it takes to run. I'd like to look at each of these in turn and compare our current setup with an "ideal" try server.
Clobber Builds Part 4 - Fixing Other Clobber Causes
In Clobber Builds Part 3, we looked at how changing the build configuration can result in broken builds, even if dependencies are perfect. Here we'll look into addressing these issues in the build system.
Combining Nodes in Graphviz
Graphviz is a handy tool for making graphs. The "dot" command in particular is great for drawing dependency graphs, though for many real-world scenarios there are simply too many nodes to generate a useful graph. In this post, we'll look at one strategy for automatically combining similar nodes so that a more understandable dependency structure is revealed.
Build System Partial Updates
There is a fairly long dev-platform thread about partial updates - specifically, running './mach build <subdirectory>'. In this post, we'll compare how this is handled in make-based systems, as well as in tup.
PGO Performance on SeaMicro Build Machines
Let's take a look at why our SeaMicro (sm) build machines perform slower than our iX machines. In particular, the extra time it takes to do non-unified PGO Windows builds can cause timeouts in certain cases (on Aurora we have bug 1047621). Since this was a learning experience for me and I hit a few roadblocks along the way, I thought it might be useful to share the experience of debugging the issue. Read on for more details!
Moving Automation Steps in Tree
In bug 978211, we're looking to move the logic for the automation build steps from buildbot into mozilla-central. Essentially, we're going to convert this:
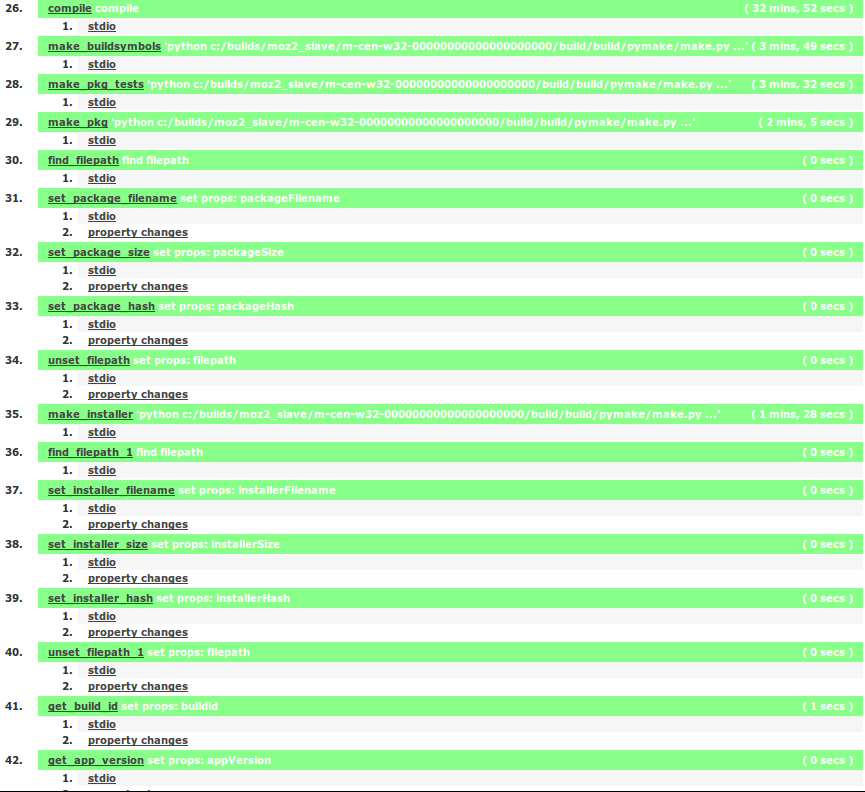
Into this:

Clobber Builds Part 3 - Other Clobber Causes
Part 3 in the clobber build series. Today we'll examine some of the reasons that even a build system with perfect dependencies would still need clobbering.
Clobber Builds Part 2 - Fixing Missing Dependencies
This is part 2 in the clobber build series. Here we'll look at how to fix the issues stemming from part 1 -- missing dependencies -- once and for all.
comments powered by DisqusAbout
![]() Hello, you've reached Mike Shal's blog. I may have some info on build systems, Linux, and/or life at Mozilla. Hopefully you will find some of it useful!
Hello, you've reached Mike Shal's blog. I may have some info on build systems, Linux, and/or life at Mozilla. Hopefully you will find some of it useful!
Categories
Archive
Links
Quotes
We've been going about this all wrong. I blame myself.
- Sandlot