Linking libxul with tup and FUSE
A significant milestone has been reached with using tup to build mozilla-central - libxul.so links! (And when copied into a make-built tree, actually runs :). However, some performance problems are quickly evident. This post looks into the cause, and works out some improvements.
Getting to libxul.so
There is a lot to build in order to get from XPIDLSRCS (back in my first post) to linking libxul.so, which is the big everything-and-the-kitchen-sink library in mozilla-central. Here's a brief summary:
- Process IPDLSRCS (different from XPIDLSRCS!).
- Generate some header files from scripts and host programs.
- Copy headers into dist/include (ugh).
- Wrap system headers in dist/system_wrappers (double ugh - no idea why this was done instead of using the -fvisibility flag).
- Compile tons of files using Mozilla's own Makefile style.
- Compile many files using NSS's Makefile style.
- Compile many files using NSPR's Makefile style.
- Compile many files from things built with gyp (media/webrtc, media/mtransport).
- Link all of the above into .desc files (fake archives), .a files (actual archives), .so files (shared libraries) using Mozilla's/NSS's/NSPR's style of linking rules.
In the end, we are able to get a libxul.so created using only configure and tup -- we don't need to run make to build any parts of the tree. Unfortunately configure right now is completely separate and needs to be run manually, but hopefully that can be integrated at some point so that it can get proper dependency checking.
Disaster Strikes (again)!
One thing is quickly apparent when linking libxul.so - it takes forever. I knew it took a long time from make builds, but this felt even worse. Here's the line from tup:
1) [39.206s] toolkit/library: SHLIB libxul.so
That's longer than I remember. And sure enough, running the linker command manually outside of tup gives a much better result:
$ time python (lots of objects and libs here...) real 0m19.206s user 0m17.049s sys 0m2.100s
So running it in tup takes over twice as long. Most other commands don't have this much overhead, so why is linking libxul.so that much different? Tup really only does two things that the shell doesn't:
- Processes are started in the FUSE file-system, rather than the base file-system. This lets tup track dependencies.
- After the process completes, tup has to update the dependencies in the database based on the file accesses (or report an error if files were accessed incorrectly).
Fortunately, it's pretty easy to separate the two to figure out how much each part is responsible for the overhead - we can just run the linker command manually, but this time do it from within the example FUSE file-system, fusexmp_fh. This is most similar to how tup's FUSE file-system is implemented, but without the dependency tracking and database. Here we go:
terminal A$ ./fusexmp_fh tmp terminal B$ cd tmp/home/marf/mozilla-central-tup/toolkit/library terminal B$ time python ... real 0m48.309s user 0m28.182s sys 0m7.592s
That's even slightly worse that in just tup (fusexmp_fh isn't an exact replica), so I think we have our culprit. The excess of FUSE activity can be seen also by running top while running the link - the FUSE file-system burns anywhere from 10-50% of a CPU, which holds back ld at ~65%. In comparison, linking locally allows ld to run at 99-100% continuously. Running the FUSE file-system with debugging flags also reveals these fun facts:
- 37426 getattr calls
- 18732 open calls
- 13 create calls
- 125373 read calls (!)
- 385665 write calls (!)
It's these last two that I'd like to get rid of - they serve no purpose for tup's dependency detection. We care about getattr, open, and create, but once a file is opened, we don't need all of the data that is read or written to go through tup. Essentially what we want is for the open() call to go to the FUSE file-system, but we want the FUSE file-system to provide the "real" file descriptor on the underlying file-system that can be used for read() and write(). This issue has come up on the tup mailing list in the past, as well as the FUSE mailing list. However, the FUSE maintainer has not sought fit to include this until other performance enhancements have proven insufficient. Of course, it is difficult to prove that this has a performance benefit without a patch to try it out, but FUSE won't be patched until we get the performance metrics. So, time to write a patch...
FUSE consists of a userspace library (libfuse.so) and a kernel-side implementation (fuse.ko, or built in to the kernel). An enhancement like this needs changes to both the kernel and userspace, so I built an Arch VM using qemu/kvm. Using a VM makes it a lot easier to test kernel changes without OOPSing the machine you're working on. It's been a while since I've used qemu, and I was actually somewhat surprised at how easy this was to setup nowadays. With kvm support, the VM is quite fast, and the default networking works just fine for my needs (I just want to ssh in, so I run it with 'qemu-system-x86_64 -m 8192 arch.qcow2 -redir tcp:2222::22 -nographic'). Getting it to run with a custom kernel was a bit of a pain, partly because I didn't bother building a new initrd, so I had to make sure that the kernel version string I was building matched the initrd that came with Arch. There's probably a better way to do that, but this worked well enough :). Soon I was able to add printk()s to the kernel source and see it in dmesg.
Patching the kernel to allow read/write passthrough is a little tricky, because we are dealing with file-descriptors in both the FUSE file-system process and the main process (ld in this case). Also it doesn't help that I don't know what I'm doing in the kernel, and have to rely on printk()ing things until I find the right place in the code. After a bit of playing around, I was able to get the FUSE userspace to pass back a pid and file-descriptor to the FUSE kernel for passthrough operations, if enabled. Things looked pretty good in the VM, but now it was time to try it out on the host OS for actual benchmarking.
After building my patch into an Ubuntu kernel, I re-ran the fusexmp_fh test:
terminal A$ ./fusexmp_fh tmp terminal B$ cd tmp/home/marf/mozilla-central-tup/toolkit/library terminal B$ time python ... real 0m24.556s user 0m20.141s sys 0m3.016s
Much better - now FUSE only adds ~27% overhead instead of 100+% (the file-system process stays under 10% CPU, and ld hovers around 95%). Still, it sounds like more overhead than necessary. One strange thing I noticed when rebooting my machine a lot (for these kernel changes) and running tests, is that my basic tup test (t4000) would run in 80ms after booting the machine, but then would slow down to 200ms after a while. That didn't seem right, especially since the CPU is idle in both cases. So I wrote a little script to run t4000 in a while loop, and compare the output of ps before and after. My hope is that when it jumps from 80ms to 200ms, I would see a new process (maybe some file-monitoring application?) that was slowing me down. To my surprise, I actually saw a process disappear during the jump: "ondemand".
It turns out that by default Ubuntu uses the "ondemand" CPU governor, which gets set about 1 minute after boot, overriding the default "performance" CPU governor. The process I saw was actually Ubuntu's /etc/init.d/ondemand, which does a "sleep 60" before setting the governor. The "ondemand" governor ramps up the CPU frequency when it hits a high usage - but as we saw from top, FUSE is holding things back from using up the CPU, so we don't always see the ramp up. Setting the governor back to "performance" gets the test back to 80ms. Now to try it with libxul...
First, we set the governor with this handy alias:
function setgov ()
{
echo "$1" | sudo tee /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor
}
After running "setgov performance", let's see how it affects our baseline native file-system link:
$ setgov performance $ time python (lots of objects and libs here...) real 0m19.188s user 0m17.045s sys 0m2.100s
Not much change - only saved about 20ms. This is expected since the ondemand governor is able to quickly adjust the CPU to the max frequency, since ld is maxing the CPU. Starting at the maximum frequency with the performance governor only gives it a slight head start. Now let's try the same thing within the FUSE passthrough file-system:
$ setgov performance terminal A$ ./fusexmp_fh tmp terminal B$ cd tmp/home/marf/mozilla-central-tup/toolkit/library terminal B$ time python ... real 0m20.191s user 0m17.285s sys 0m2.156s
Now we are only at 5% overhead with FUSE - not too bad overall, since this is what allows us to get dependency detection. What if we just used the performance governor in the first place? It brings the runtime down to 28.579s - not as good as using the passthrough implementation, but still better than the default. So it seems the ondemand governor does not play too nicely with FUSE, but the main holdup is from passing all those reads and writes back through userspace. Using both the passthrough implementation and performance governor, now we can run in tup again:
1) [18.866s] toolkit/library: SHLIB libxul.so
Hmm, now why is that *faster* than native? Yaaarg...
Anyway, still lots to do before we can get a full build with tup, and then it's time to convert it all to moz.build! In the meantime, here is a cool graph of all the runtimes discussed on this page:
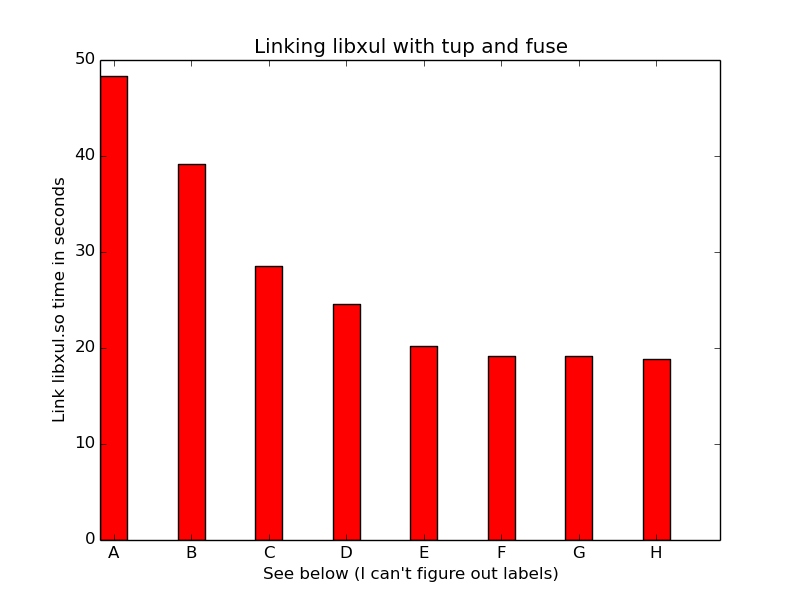
- fuse default
- tup default
- fuse default, performance governor
- fuse passthrough
- fuse passthrough, performance governor
- native
- native, performance governor
- tup passthrough, performance governor
About
![]() Hello, you've reached Mike Shal's blog. I may have some info on build systems, Linux, and/or life at Mozilla. Hopefully you will find some of it useful!
Hello, you've reached Mike Shal's blog. I may have some info on build systems, Linux, and/or life at Mozilla. Hopefully you will find some of it useful!
Categories
Archive
Links
Quotes
We've been going about this all wrong. I blame myself.
- Sandlot