PGO Performance on SeaMicro Build Machines
Let's take a look at why our SeaMicro (sm) build machines perform slower than our iX machines. In particular, the extra time it takes to do non-unified PGO Windows builds can cause timeouts in certain cases (on Aurora we have bug 1047621). Since this was a learning experience for me and I hit a few roadblocks along the way, I thought it might be useful to share the experience of debugging the issue. Read on for more details!
Background - What is PGO?
In case you haven't heard of it before, PGO stands for Profile-Guided Optimization. PGO builds at Mozilla add a few steps to a normal build -- after the first pass, the browser is launched with a few pages to exercise the application and collect profiling statistics. We then do a second pass and tell the linker to use that profiling information to make smarter optimization decisions. The benefit with PGO is that we get faster startup times and performance benchmarks. The downside is that build times can be painfully slow -- the buildbot timeout we are hitting in bug 1047621 is 3 hours. And that's just for the final link! Of course, for a release we only have to pay the price of PGO once, while users can get the benefits every time they launch and use Firefox.
Why We Started Hitting Timeouts
For this particular bug, we are unable to complete a PGO Windows build, but only if the build runs on an sm machine. Buildbot ends up killing the job with the following error: "command timed out: 10800 seconds without output, attempting to kill". We have a timeout set in buildbot that kills the build process if there's no output for 3 hours, and that's what we're hitting here. (Separately, there's a longer overall timeout that can cause trouble in other cases). The last line before the buildbot timeout is the command to run the second pass of the PGO link. Here's a comparison of the output for an ix machine vs an sm machine:
ix output
xul.dll (long linking command with -LTCG:PGUPDATE goes here) PGOMGR : warning PG0188: No .PGC files matching 'xul!*.pgc' were found. Creating library xul.lib and object xul.exp Generating code Still linking, 30 minutes passed... Still linking, 30 minutes passed... 4523 of 181972 ( 2.49%) profiled functions will be compiled for speed Still linking, 30 minutes passed... 181972 of 181972 functions (100.0%) were optimized using profile data 7346037602 of 7346037602 instructions (100.0%) were optimized using profile data Finished generating code
sm output
xul.dll (long linking command with -LTCG:PGUPDATE goes here) command timed out: 10800 seconds without output, attempting to kill
By the number of "Still linking, 30 minutes passed" messages, you can see that this link step takes somewhere between 1.5 - 2 hours on the ix machine. Curiously, the messages are missing entirely from the sm build. I've seen builds break this way before -- sometimes Windows will decide to pop up a window about a crashed process instead of killing the process so make knows it failed. Make keeps waiting for the process to return, but it doesn't until the user interacts with the machine (since this is automation, there is no "user"). Buildbot patiently waits the 3 hours and then kills the job.
So I logged into a machine with VNC and ran the PGO link command, expecting a window to tell me what was broken. To my surprise, the library actually linked successfully! So why would it work for me, but not in a real build? It turns out that the "Still linking" messages are getting buffered by one of our wrapper python scripts, so they didn't have the intended effect of preventing buildbot from stopping the build. Also, the full runtime of the job on the sm machines is just over the limit, at 3 hours and 6 minutes. It seems we added just enough code on the Aurora branch to start hitting the timeout. Fixing the "Still linking" messages to be unbuffered isn't too hard, so that's one thing we'll be landing for this bug. However, it still doesn't address the question of why ix machines can do this in under 2 hours, while the sm machine takes over 3.
Analyzing PGO
There are some common suspects with a performance difference like this: CPU, memory, or I/O speed. The CPUs are fairly similar -- both are clocked at 2.4Ghz, but slightly different processor families (Xeon X3430 for the ix, and Xeon E3-2165L for the sm). The sm actually has more memory, with 16GB compared to ix's 8GB, so it's unlikely that memory pressure / swapping is causing the problem. I'm not sure what the disk specs are, but if this were Linux, a few dd commands or hdparm would help gather some I/O statistics.
One of the tools that was introduced to me while working on this bug was Xperf. The MSDN docs aren't very noob-friendly, but fortunately we have an easier guide on MDN. Basically, you start up xperf with the things you want to collect, run your job, then run xperf again to output the stats. Here's the script I was using:
rm xul.dll xperf -on latency -stackwalk profile time ../../../../mozmake MOZ_PROFILE_USE=1 xperf -d out.etl
Some notes:
- If you want to test a long-running job like PGO, you might want to pay special attention to -SetProfInt to set the profiling interval. Unfortunatley I didn't know about it the first time, and ended up with 5+GB trace files.
- On our build machines, xperf lives in C:\Program Files (x86)\Windows Kits\8.0\Windows Performance Toolkit. When I installed it in my VM, it ended up at C:\Program Files\Microsoft Windows Performance Toolkit. Neither of these are in PATH by default, so you'll want to add it in.
I was hoping to get both of these xperf traces down to my local VM for comparison, but sftp was being weird and copying past 100% of the file. It turns out Msys only has a 32-bit size field so the reported size is missing a few bits. What I thought was a 700MB file was actually a 5GB file. Now I regret not finding the -SetProfInt option earlier, since doing it now means another 3 hour link time. (You can convert these .etl files to .csv, and then take every Nth line of the csv to downsample after the fact, but the csv itself ended up being 30GB after several hours of conversion, and well, ugh.)
Unfortunately the .etl file was too large to load on the sm machine, but I was able to at least view the one from the ix machine. Here are a few relevant graphs:
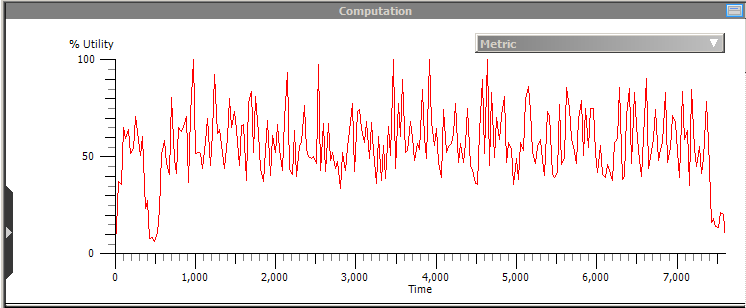
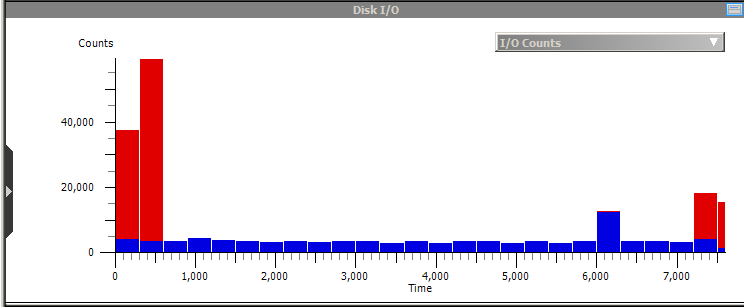
As you can see, there is a burst of disk activity up front (the large red bars indicate reading all the library and object files), then a long period of CPU intensive activity, followed by a burst of disk at the end (writing out the output). The disk activity accounts for about 10-15 minutes of the run-time on the ix machine. Although I wasn't able to load the sm graph to directly compare, it is unlikely (though not impossible!) that we have such a slow disk that this 10-15 minutes takes an hour longer on the sm machine. By this time, I was getting pretty sick of waiting for these 2-3 hour jobs to complete, so I started some smaller benchmarks to get a quicker turnaround time.
Test1 (read 1GB file): cat testfile.dat > /dev/null
- ix: 2.0s
- sm: 3.2s
With this test I'm just reading 1GB of data. Unfortunately I don't really know how Windows handles caching, so I didn't know if the hard disk could still be affecting this test or not.
Test2 (md5sum 1GB of data): ./ok.exe | md5sum
- ix: 5.6s
- sm: 10.1s
With this test I'm trying to avoid using the disk entirely. The 'ok.exe' test program just spits out 1GB of data, and then we md5sum it to do some work. As you can see, the sm takes almost twice as long to do the same work, even though it's a nearly identical processor running on the same OS! The power management settings look like they were maxed on the sm machine, so I wouldn't expect Windows to be throttling back to save power.
Taras suggested checking the CPU temps to see if they might be causing the cores to throttle back prematurely. Unfortunately Windows doesn't have a built-in way to check this, but there are several options you can download. I tried the one called CoreTemp, which looks like this:
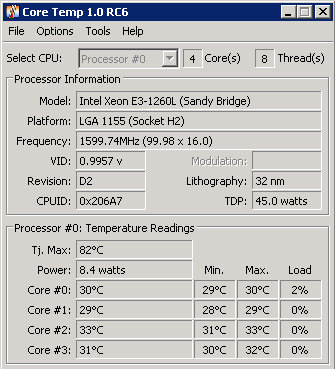
Although I didn't see anything out of the ordinary in the temperature readings, fortunately this also showed us the processor frequency. On the ix machine, when running a heavy load (such as the md5sum test), the frequency jumps from its idle usage of ~1700MHz up to its max of ~2500MHz. However, the sm machine (shown in the picture), is stuck at 1599.74MHz no matter what's happening on the system! Finally, we have something that points to an actual issue. Plus the fact that the processor is stuck at 2/3 its max frequency while PGO takes about 3/2 times as long is reassuring that we have the culprit. Hopefully bug 1050508 will be fixed soon. Until then, we also have bug 1055876 which is a performance problem the other way - the ix machines are slower than sm in some cases!
comments powered by DisqusAbout
![]() Hello, you've reached Mike Shal's blog. I may have some info on build systems, Linux, and/or life at Mozilla. Hopefully you will find some of it useful!
Hello, you've reached Mike Shal's blog. I may have some info on build systems, Linux, and/or life at Mozilla. Hopefully you will find some of it useful!
Categories
Archive
Links
Quotes
We've been going about this all wrong. I blame myself.
- Sandlot