A First Tupfile
In this example, we'll create a small C program using tup. The program itself will be completely useless, but hopefully you can use your imagination to see how you might use tup in a real project. Let's start with a typical "Hello, world!" in C. Since we're using tup, you'll want to run tup init at the top of the project, which in this example will be the tup_test directory.
$ mkdir tup_test $ cd tup_test $ tup init $ EDITOR hello.chello.c
#include <stdio.h>
int main(void)
{
printf("Hello, world!\n");
return 0;
}
Here's what we have so far:
$ ls -a
. .. .tup hello.c
The .tup directory contains the dependency database, and some lock files. You shouldn't mess with files in this directory manually, unless you want to play around. If there was a warranty for tup, you would lose it by doing that.
If you were going to compile hello.c manually, you might run something like gcc hello.c -o hello. Instead of doing that, however, we'll put that exact string in a Tupfile (along with some additional annotations).
Tupfile: hello.c |> gcc hello.c -o hello |> hello
This line we typed is known as a ":-rule", since the line begins with a :. You can see the gcc command in between the |> symbols. The file listed on the left side is the input, and the file listed on the right side is the output. Ignore the redundancy for now -- we'll fix that later.
Now that you have a Tupfile to tell tup what to do, you can run tup to start the build process. If all goes well, you should see something like the following, only with more colors and cool progress bars:
$ tup [ tup ] Scanning filesystem...0.007s [ tup ] No tup.config changes. [ tup ] Parsing Tupfiles... [ 1/1 ] . [ tup ] No files to delete. [ tup ] Executing Commands... [ 1/1 ] gcc hello.c -o hello [ tup ] Updated. $ ls Tupfile hello hello.c $ ./hello Hello, world!
You can try to run tup again to verify that the file isn't compiled unnecessarily (since it hasn't been changed). Then you can edit the file and see that it *is* rebuilt:
$ tup [ tup ] Scanning filesystem...0.000s [ tup ] No tup.config changes. [ tup ] No Tupfiles to parse. [ tup ] No files to delete. [ tup ] No commands to execute. [ tup ] Updated. $ EDITOR hello.chello.c
#include <stdio.h>
int main(void)
{
printf("Hello, world!\n""Hi, everybody!\n");
return 0;
}
$ tup [ tup ] Scanning filesystem...0.006s [ tup ] No tup.config changes. [ tup ] No Tupfiles to parse. [ tup ] No files to delete. [ tup ] Executing Commands... [ 1/1 ] gcc hello.c -o hello [ tup ] Updated. $ ./hello Hi, everybody!
Finally, we will try to change the gcc command string itself. In this case, we won't change the hello.c file, only the Tupfile.
Tupfile: hello.c |> gcc -Wall hello.c -o hello |> hello
$ tup
[ tup ] Scanning filesystem...0.007s
[ tup ] No tup.config changes.
[ tup ] Parsing Tupfiles...
[ 1/1 ] .
[ tup ] No files to delete.
[ tup ] Executing Commands...
[ 1/1 ] gcc -Wall hello.c -o hello
[ tup ] Updated.
Since the Tupfile changed, you can see that the top-level directory (represented by .) had to be re-parsed. Tup then saw that the command changed, so the new command was executed, even though hello.c was unchanged.
If you only ever want one C file, you can continue modifying this example as long as you like. Just edit the Tupfile when you want to change how the program is built, and edit the C file when you want to change the program itself.
Read on for other examples to see how to build more than one file, and make the Tupfiles less redundant and more manageable.
A Program Grows
Continuing from the previous example, we will build on the Hello World program by adding a new C file. Like any useless program example, this file will provide a function to square a number.
square.c#include "square.h"
int square(int x)
{
return x * x;
}
square.h
int square(int x);hello.c
#include <stdio.h> #include "square.h" int main(void) { printf("Hi, everybody!\n"); printf("Five squared is: %i\n", square(5)); return 0; }
Now we can try to build the new program:
$ tup
[ tup ] Scanning filesystem...0.007s
[ tup ] No tup.config changes.
[ tup ] Parsing Tupfiles...
[ 1/1 ] .
[ tup ] No files to delete.
[ tup ] Executing Commands...
[ 1/1 ] gcc -Wall hello.c -o hello
/tmp/ccClookD.o: In function `main':
hello.c:(.text+0x1d): undefined reference to `square'
collect2: ld returned 1 exit status
*** tup errors ***
*** Command ID=6 failed with return value 1
Oops, that obviously didn't work, since we forgot to actually compile and link the new C file. Let's do that now.
Consider how you might build this program with the shell, keeping scalability in mind. As a first step, you would probably compile each C file individually with gcc -Wall -c hello.c -o hello.o and gcc -Wall -c square.c -o square.o. Similar to before, we will type these compilation commands exactly as is in the Tupfile, and add the input/output annotations. Note that we change the first :-rule to use -c and output to hello.o instead of hello. After you've made the changes, run tup.
Tupfile: hello.c |> gcc -Wall -c hello.c -o hello.o |> hello.o : square.c |> gcc -Wall -c square.c -o square.o |> square.o
$ tup [ tup ] Scanning filesystem...0.007s [ tup ] No tup.config changes. [ tup ] Parsing Tupfiles... [ 1/1 ] . [ tup ] Deleting files... [ 1/1 ] hello [ tup ] Executing Commands... [ 1/2 ] gcc -Wall -c square.c -o square.o [ 2/2 ] gcc -Wall -c hello.c -o hello.o [ tup ] Updated. $ ls Tupfile hello.c hello.o square.c square.h square.o $ ./hello bash: ./hello: No such file or directory
Since we changed the first rule to compile hello.o instead of hello, the main executable is no longer generated. Tup sees this, and removes hello from the filesystem. In this way, tup always keeps your build as if you had just built everything from scratch. This is why you don't ever have to write or manually invoke a "clean" target, like you do in most other build systems.
To finish the Tupfile, let's go ahead and add the linker rule:
Tupfile: hello.c |> gcc -Wall -c hello.c -o hello.o |> hello.o
: square.c |> gcc -Wall -c square.c -o square.o |> square.o
: hello.o square.o |> gcc hello.o square.o -o hello |> hello
$ tup [ tup ] Scanning filesystem...0.006s [ tup ] No tup.config changes. [ tup ] Parsing Tupfiles... [ 1/1 ] . [ tup ] No files to delete. [ tup ] Executing Commands... [ 1/1 ] gcc hello.o square.o -o hello [ tup ] Updated. $ ./hello Hi, everybody! Five squared is: 25
One thing you may have noticed is that both C files include the square.h header, but we haven't specified it as an input to the command. You may be surprised to see that we can still change the header and cause both files to recompile to pick up the change:
square.hint square(int x);
#define SECRET 42
$ tup
[ tup ] Scanning filesystem...0.007s
[ tup ] No tup.config changes.
[ tup ] No Tupfiles to parse.
[ tup ] No files to delete.
[ tup ] Executing Commands...
[ 1/3 ] gcc -Wall -c square.c -o square.o
[ 2/3 ] gcc -Wall -c hello.c -o hello.o
[ 3/3 ] gcc hello.o square.o -o hello
[ tup ] Updated.
The trick is that tup instruments all commands that it executes in order to determine what files were actually read from (the inputs) and written to (the outputs). When the C preprocessor opens the header file, tup will notice that and automatically add the dependency. In fact, we don't have to specify the C input file either, but you can leave that in there for now since we'll use it in the next section.
A Simpler Tupfile
Let's take a closer look at the Tupfile from before:
Tupfile: hello.c |> gcc -Wall -c hello.c -o hello.o |> hello.o : square.c |> gcc -Wall -c square.c -o square.o |> square.o : hello.o square.o |> gcc hello.o square.o -o hello |> hello
The first :-rule has been highlighted to show the redundant information. It's pretty annoying whenever you have to type something twice, so we'll get rid of the duplication. To do that, we'll make use of tup's %-flags. The %f flag can be used to represent the inputs, while the %o flag can be used to represent the outputs. Let's change each of the rules to use these new flags:
Tupfile: hello.c |> gcc -Wall -c hello.c%f -o hello.o%o |> hello.o : square.c |> gcc -Wall -c square.c%f -o square.o%o |> square.o : hello.o square.o |> gcc hello.o square.o%f -o hello%o |> hello
You should now have:
Tupfile: hello.c |> gcc -Wall -c %f -o %o |> hello.o : square.c |> gcc -Wall -c %f -o %o |> square.o : hello.o square.o |> gcc %f -o %o |> hello
An easy way to see that your Tupfile refactoring didn't cause any functional changes is to run tup refactor. If the commands expand to the same string, you will only see the Tupfile being re-parsed, followed by "No files to delete" message:
$ tup refactor
[ tup ] Scanning filesystem...0.007s
[ tup ] No tup.config changes.
[ tup ] Parsing Tupfiles...
[ 1/1 ] .
[ tup ] No files to delete.
More!
There is still some more redundancy we get get rid of:
Tupfile: hello.c |> gcc -Wall -c %f -o %o |> hello.o : square.c |> gcc -Wall -c %f -o %o |> square.o : hello.o square.o |> gcc %f -o %o |> hello
In this case we'll want to make the output file the same name as the input file, only with a different extension. We can use some %-flags in the output file list as well. For example, %B (basename, no extension) will be replaced with the input filename, minus any directory and extension information. Let's use it in the output section now:
Tupfile: hello.c |> gcc -Wall -c %f -o %o |> hello.o%B.o : square.c |> gcc -Wall -c %f -o %o |> square.o%B.o : hello.o square.o |> gcc %f -o %o |> hello
If you run tup refactor again you should not see any errors.
More! More!
Continuing our efforts to remove redundancy, let's take another look at the first two rules:
Tupfile: hello.c |> gcc -Wall -c %f -o %o |> %B.o : square.c |> gcc -Wall -c %f -o %o |> %B.o : hello.o square.o |> gcc %f -o %o |> hello
Here you can see we have two rules that differ only in their input filename - both the command string and output string are identical (even though they evaluate to different values). We can combine these rules into one using the foreach keyword. The foreach keyword iterates over the input list in a loop, and creates a new rule for each one. Since we have two inputs, there are two new rules, which exactly correspond to the two separate rules we had written earlier.
Tupfile: foreach hello.c square.c |> gcc -Wall -c %f -o %o |> %B.o : square.c |> gcc -Wall -c %f -o %o |> %B.o : hello.o square.o |> gcc %f -o %o |> hello
Once again verify that no functional changes have been made by running tup refactor.
MMMMMMMMMore!
By now you can see that there isn't a whole lot of redundancy left. One thing that may not be apparent is that the Tupfile is redundant with the directory itself!
Tupfile: foreach hello.c square.c |> gcc -Wall -c %f -o %o |> %B.o : hello.o square.o |> gcc %f -o %o |> hello
$ ls *.c
hello.c square.c
If you like explicitly listing the source files, you are certainly free to do so. However, you might like to just be able to create a new C file in the directory and have it automatically get compiled and linked in. To do so, just use the globbing feature:
Tupfile: foreach hello.c square.c*.c |> gcc -Wall -c %f -o %o |> %B.o : hello.o square.o*.o |> gcc %f -o %o |> hello
One thing to note is that the file globbing does not take place on the filesystem, but rather the tup database itself. Consider if we had used this Tupfile before we ever created hello.o or square.o - the *.o wouldn't have anything to match! However, when tup parses the foreach rule, the new files are added to the tup database before they are created in the filesystem. This way the *.o will match the files, and the proper linker rule will be generated.
A Brief Look Inside Tup
Let's take one last look at the final Tupfile for this example:
Tupfile: foreach *.c |> gcc -Wall -c %f -o %o |> %B.o : *.o |> gcc %f -o %o |> hello
It doesn't look too much like a shell script anymore. Fret not, for the script is still in tup! However, it is not a true shell script, but rather a graph of commands connected by their inputs and outputs. If you have Graphviz installed (which gives you the dot program), you can generate a graph like so:
$ tup graph . | dot -Tpng > ~/hello.png
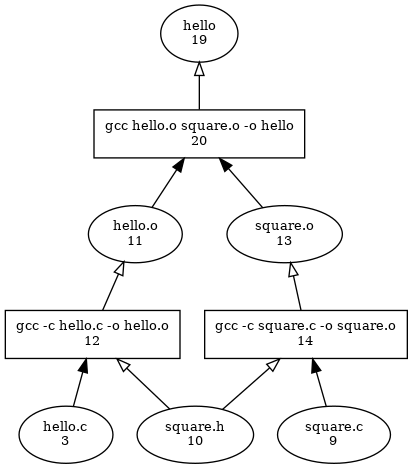
If you were to make a topological sort (Wikipedia) of the graph, keeping only the rectangle shaped nodes, you would have your shell script again. When tup gets to the final stage of its processing and actually goes to execute commands, it will start with the files you changed (like hello.c) and follow the arrows upward until there are no more arrows to follow. Try starting at each of the three base files and see which commands will be executed. It also works for any combination of inputs. In this way, you can think of the tup database as a collection of 2^n shell scripts, where n is the number of input files (since each file can be either "modified" or "unmodified", you get an exponential number of possible fileset changes). Depending on which files you modified, tup will pick out the smallest shell script that updates everything quickly and correctly. Of course, the shell script is generated on the fly using the graph - storing an exponential number of shell scripts would be crazy.
This is merely scratching the surface of how tup works - there is much more than just picking out the correct rectangles! After all, those dots and lines have to get in the graph in the first place...