Combining Nodes in Graphviz
Graphviz is a handy tool for making graphs. The "dot" command in particular is great for drawing dependency graphs, though for many real-world scenarios there are simply too many nodes to generate a useful graph. In this post, we'll look at one strategy for automatically combining similar nodes so that a more understandable dependency structure is revealed.
Graphing C Programs
The "dot" command is great for graphing simple C programs. For example, here is what a program with two C files might look like:
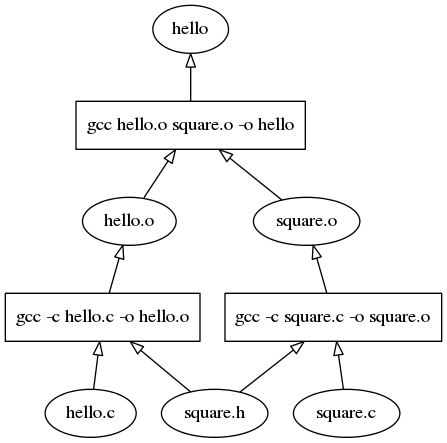
It's pretty easy to see the structure and understand what's going on. However, most programs don't have only two files. Let's look at a small program of only ~40 C files (plus a similar amount of header files) and see if the graph is still useful:

Unfortunately even with this small number of nodes, there is too much information in the graph to produce something of value. Even if you generate a large image so that you can zoom in and read the nodes, the overall structure is lost. Of course, things aren't any better when we get to slightly larger programs, like this piece of libavcodec at ~400 C files:

That isn't a horizontal line - it's what you get when you zoom out of a graph with a fairly flat dependency hierarchy and lots of files.
Combining Nodes
One solution I've found for this is to combine nodes that are similar. What constitutes "similar" may depend on what exactly you're graphing. For a simpler graph where all node are the same type (unlike the previous graphs that have command nodes and file nodes), it may be sufficient to say that one node is similar to another if its inputs and outputs point to the same nodes. Let's use the following example:
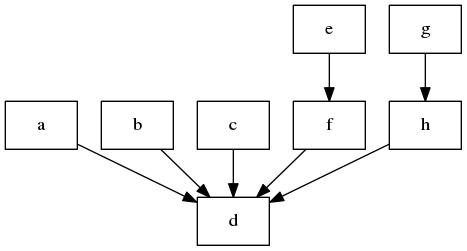
Objectively we could say that nodes "a", "b", and "c" are similar to each other, though these aren't similar to "f" or "h" since those two nodes also have incoming links. The following rough pseudo-code would accomplish this:
foreach node N {
calc_hash(N)
}
foreach unique hash {
combine all nodes with this hash
}
The calc_hash() function is where we put our specific logic for determining "similar" nodes. For this case where we just want to combine nodes that have the same inputs and outputs, we could do something like this:
calc_hash(node N)
{
h = new hash();
foreach link in N.inputs {
h.update(link output)
}
foreach link in N.outputs {
// Use a negative sign here so that
// A->B is different from B->A
h.update(-link input)
}
}
In other words, we generate a hash by iterating over the inputs and outputs and hashing them together (we are assuming the inputs & outputs are sorted here). By combining nodes with the same hash, we would end up with the following graph:
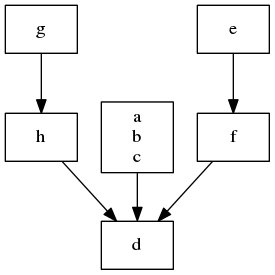
Depending on your particular use-case, you could change the hash function to say that the g->h->d chain is similar to the e->f->d chain, resulting in an even slimmer graph.
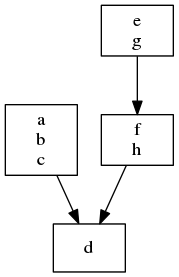
The overall structure is readily apparent - we can see that everything depends on "d", and is either one or two steps away.
Combining Nodes for C Programs
Combining nodes in C programs is slightly more complicated, at least when tup's notation with separate command nodes and files nodes is used. Tup's internal combining algorithm does two passes over the DAG: first, it combines similar commands by looking at chains of commands; second, it combines similar files by looking at the immediate inputs and outputs of the file. The two-C-file program from before would look like this when combined:
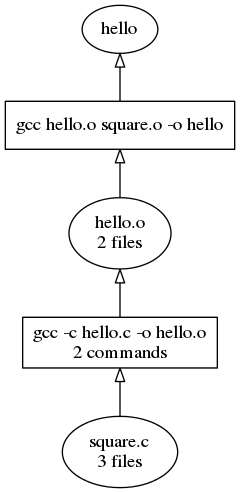
If instead the program had a longer chain, such as by adding a third C file that is generated from a python program, the full graph might look like this:
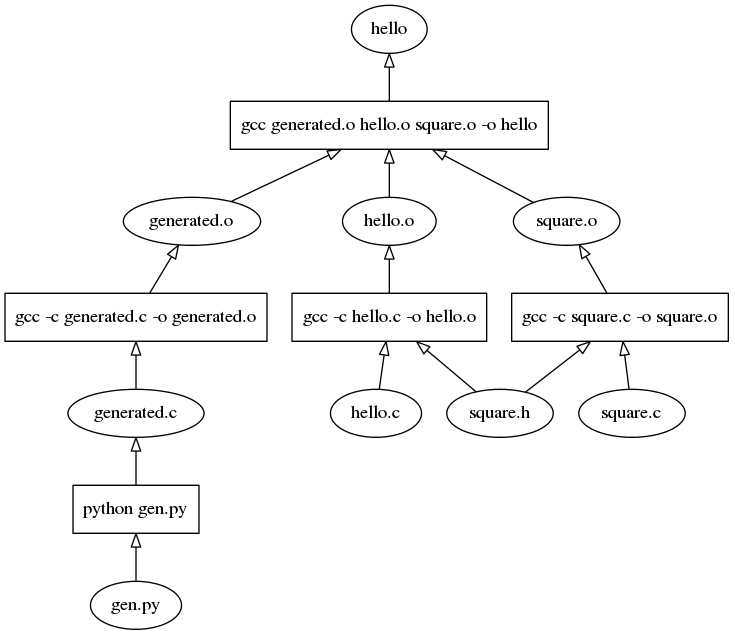
When combined, we can still see that the code generation chain is separate from the regular compiler chain. This gives us a view of the overall structure, without bogging down the graph:
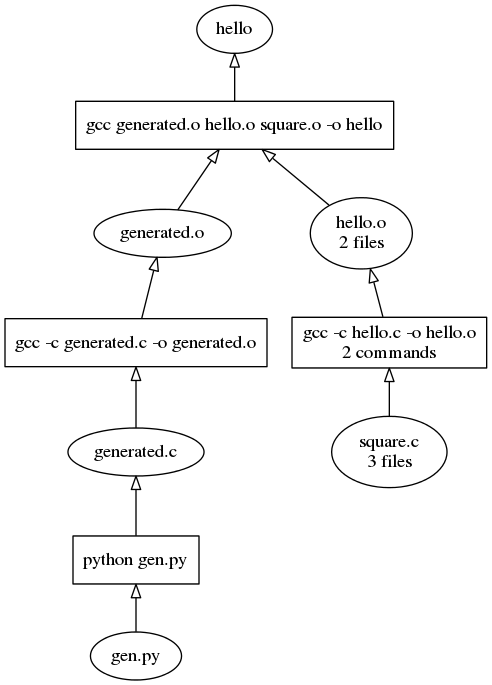
The difference may not be so apparent when only two command chains are combined, so let's head back to the 40 and 400 C file examples. Here's a combined graph of some of the source code used to build tup itself (the 40 C file case):
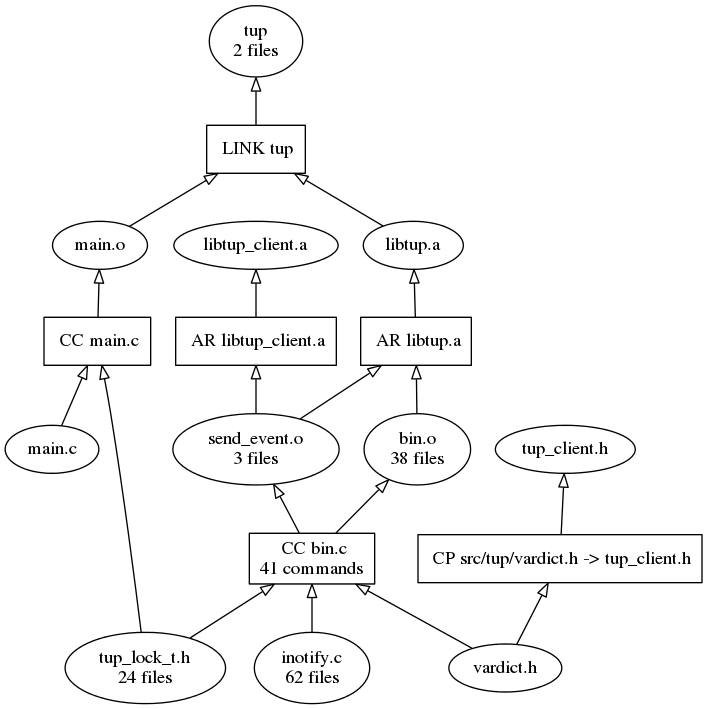
Now it's fairly easy for anyone who is unfamiliar with the project to get a high-level view of the structure of the program. We can see that most of the code goes into some library files, which are linked with a main file to produce the final executable. Fortunately, this approach also scales to the 400 C file example, so let's combine the libavcodec graph and see what we get:
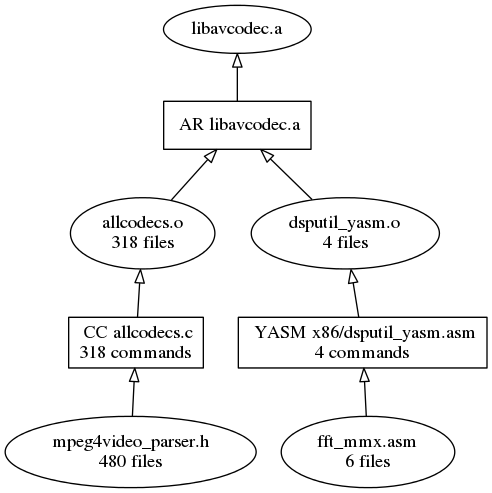
While before we had an unreadable graph, now we know that libavcodec is just a bunch of C code with a little bit of assembly mixed in. It turns out that when you get down to it, the structure of libavcodec is no more complicated than a simple hello-world program. It just has 400 times more files!
Future Work
This was just something I was playing around with to get useful dependency graphs from things that were built with tup. I also found it handy to use the same technique while trying to figure out the dependency hierarchy of the web of included mozconfigs, though even with combined nodes the graph is still a complete mess:

I guess there is still some work to do either in the combining algorithm, or in cleaning up our mozconfigs!
comments powered by DisqusAbout
![]() Hello, you've reached Mike Shal's blog. I may have some info on build systems, Linux, and/or life at Mozilla. Hopefully you will find some of it useful!
Hello, you've reached Mike Shal's blog. I may have some info on build systems, Linux, and/or life at Mozilla. Hopefully you will find some of it useful!
Categories
Archive
Links
Quotes
We've been going about this all wrong. I blame myself.
- Sandlot