Build System Partial Updates
There is a fairly long dev-platform thread about partial updates - specifically, running './mach build <subdirectory>'. In this post, we'll compare how this is handled in make-based systems, as well as in tup.
What is a Partial Update?
Partial updates are when a developer consciously decides to truncate the build graph in some fashion in order to achieve a quicker turn-around time. This can be done for two reasons:
- The developer knows that many files will be updated from the build, but is only interested in iterating on a small subset.
- The developer knows exactly what files need to be updated from the build, and can figure it out faster than the build system.
The first reason is a perfectly valid use-case. For example, while editing a header file used by many C files, the developer may initially only care about getting a single C file to compile correctly. Once that file is working, a full update can be done to build the rest of the files. Waiting for the build system to compile 100 files that you don't care about before it gets to the 1 that you do care about is a waste of time.
The second reason is, of course, completely ridiculous. It is only because developers are so tied to inefficient build systems that this reason even exists. Where else in the world of computing is it acceptable for a human to out-think a computer in a problem that is purely algorithmic with a well-defined dataset and bounded runtime?
As an example, consider the following dependency graph from make:
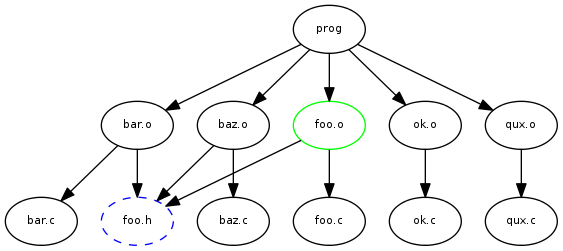
We might be editing foo.h (dashed blue outline), and initially we only care about getting foo.o to compile properly (green outline). Fortunately, make does the right thing here if we do 'make foo.o' - it will start at the green node, and look at the two dependencies (foo.h and foo.c), decide that it needs to recompile, and finish. Make doesn't need to visit any other nodes in the DAG. In particular, bar.o and baz.o won't be recompiled, nor will prog be re-linked, until a full build.
The downside to this approach lies in make's core algorithm, which is:
- Construct a global DAG from Makefiles and generated dependency files (eg: .d files from gcc).
- Start at the requested targets (such as 'foo.o'), and walk down the DAG.
The first step can cause problems, where 'make' inefficiently loads the full DAG before doing anything. As you can see from the graph, changing foo.h will never result in causing qux.o or ok.o to be rebuilt, and yet 'make' has to load those nodes and dependencies into the graph every time it starts up. For two nodes that won't make a difference, but consider if there are hundreds or thousands of other irrelevant targets. Why do we care to parse all of their dependency files and load them into the DAG only to ignore them when we walk through it? Such unnecessary work wastes developer time.
Developers hate it when their time is wasted, so they'll find ways around it. After all, they can figure out what to build faster than the build system can. Suppose our project was partitioned into directories as in the following graph, using a recursive make system:
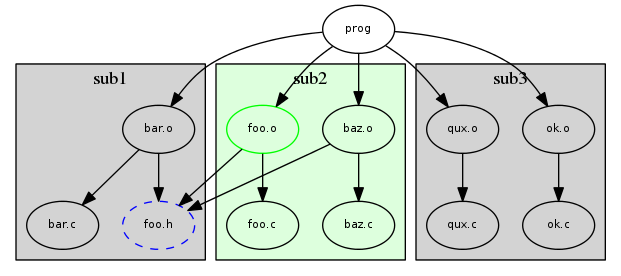
Since the developer knows they only want foo.o to be built, they can run 'make' inside the 'sub2' directory. This will help speed things up tremendously, since make won't have to load the two gray sections of the DAG (which could be many times larger than depicted). Unfortunately, by arbitrarily partitioning the DAG among directory boundaries, we are more likely to miss important dependencies, as is discussed in Recursive Make Considered Harmful (RMCH). Consider if foo.h was not a regular file checked into version control, but instead generated by a python script:
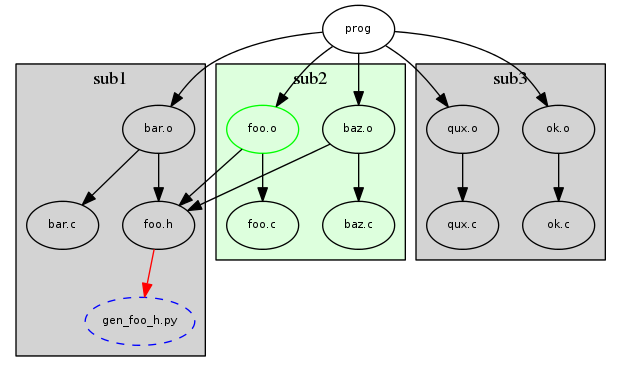
Now the developer can create a new header file by editing gen_foo_h.py, but the knowledge on how to create the header from it is missing when we just run make in 'sub2', as denoted by the red link. This is the classic problem as described in RMCH. Of course, the remedy in RMCH is to just load the global DAG, but as we've already seen, that can be too slow for large projects!
Partial DAG & Partial Updates
In Build System Rules and Algorithms, I argue that a build system should use a Partial DAG (PDAG) instead of the global DAG that make/SCons/ninja/etc use. Let's see how this would play out in the same case. The PDAG loaded by the build system when gen_foo_h.py is modified looks like this:
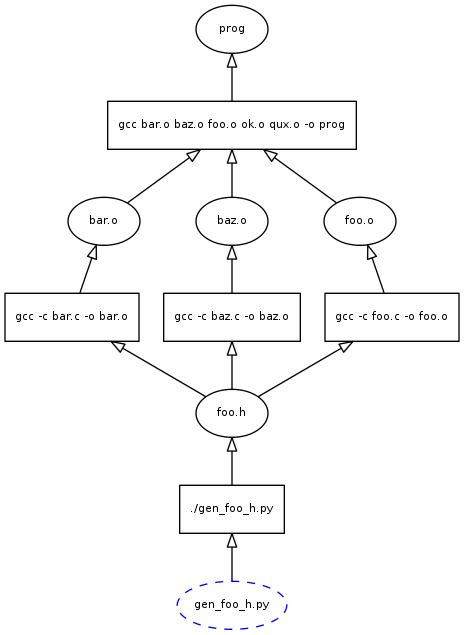
This already has benefits over the make approach, because we aren't loading all of the unnecessary pieces of the DAG. In particular, files like qux.o and ok.o are no longer present. The build system doesn't need to consider them at all!
However, if we build all the files in this PDAG, the turn-around time may still be too slow for a developer if they are only interested in seeing the results of a single compilation. Fortunately, it is easy to prune the PDAG down to the parts that the developer cares about. All we need to do is start at the requested file (foo.o) and walk the DAG backward, marking all of the nodes along the way. The unmarked nodes can just be removed from the graph. This results in the following PDAG:
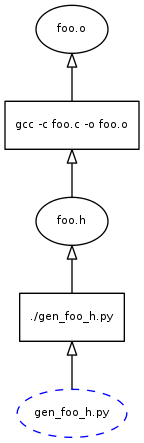
Note that it has all the nodes we care about, and none of the ones we don't. Since it's using the efficient Partial DAG construction algorithm, we don't have to worry about arbitrarily segmenting the graph along directory boundaries in order to get acceptable performance. That means it has all of the required dependencies, so we won't be skipping commands that need to run in other directories.
You can still prune the PDAG down to build all of the object files in a particular directory, of course (eg: to build a subtree). This is fundamentally different from how make operates, however. Using the Partial DAG, dependencies in the whole tree are considered, so we avoid the problems described in RMCH and get correct build results. The build just stops once those select files are updated.
For a real example from the mozilla-central tree built with tup, let's change a well-used header file (jsapi.h) and take a look at the pruned PDAG if we are only interested in jsapi.o:
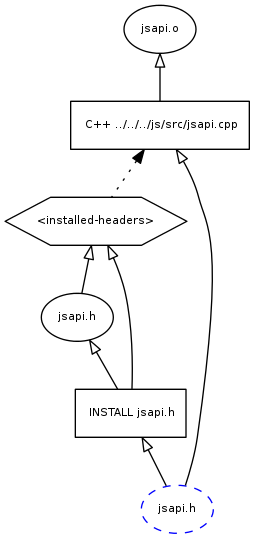
Building and pruning the PDAG takes 70ms, which is fairly long due to the fact that the PDAG for jsapi.h is large, comprising ~1500 C++ files. In contrast, building and pruning a PDAG for jsapi.cpp is only 4ms. Note this is from a tree over a year ago, so it was before unified sources. Still, we can be editing a well-used file like this, execute a partial update on a single file, and start compiling it in less than a tenth of a second. This is a short enough time for a developer to not notice while iterating. It is certainly much faster than it would take a developer to figure out in which directories to manually invoke 'make'!
comments powered by DisqusAbout
![]() Hello, you've reached Mike Shal's blog. I may have some info on build systems, Linux, and/or life at Mozilla. Hopefully you will find some of it useful!
Hello, you've reached Mike Shal's blog. I may have some info on build systems, Linux, and/or life at Mozilla. Hopefully you will find some of it useful!
Categories
Archive
Links
Quotes
We've been going about this all wrong. I blame myself.
- Sandlot