Getting data out of the Mozilla build configuration
Last time when looking at building mozilla-central with tup, we ran into some issues with converting the various m-c data formats into tup rules. In particular, the time to parse all the data is way slower than necessary, and the feature used to parse the data is not yet supported on Windows. In this post we'll look at an alternate method, and compare the pros & cons. Then we'll look into what is needed to get tup in the m-c tree and supported as an official build backend.
Getting data out of the Mozilla build configuration
As mentioned in the previous post, the m-c tree contains a number of different data formats that define the build configuration. Among them are:
- Configuration data from 'configure', stored in config.status (a python script), and autoconf.mk (for make). This is currently unchanged by tup.
- moz.build files that define variables (eg: CPP_SOURCES, EXPORTS, etc)
- Makefile.in files that have some things yet to be converted to moz.build, as well as random custom rules and targets.
- Makefiles for NSS in security/nss/, which have a different format and rules.
- Makefiles for NSPR in nsprpub/, which have yet another format.
- A few GYP files for third party projects that are built from gyp.
Tup itself has 3 primary ways to parse data into rules:
- Tupfiles (with rules like ': foo.c |> gcc foo.c -o foo.o |> foo.o')
- Lua scripts with functions to create rules (tup.rule('blah blah'))
- Run an external script (eg: python, shell, etc) to print Tupfile rules to stdout
The Tupfile parser can read most data-driven Makefiles directly, so long as they contain only variable assignments and if statements. However, that doesn't help at all for the moz.build files, gyp files, or the random custom rules that exist in all the Makefiles. The Lua scripting capability can be used to parse anything, at least in theory. However, given the number of data formats it would need to support, it would take a lot of time and debugging to do so. The last option is what we used in the previous post, which is to have tup shell out to a python script to parse the various data files. Python was a natural choice given the circumstances:
- config.status is already python
- moz.build files are already python
- Makefiles can be parsed in python using pymake
- .gyp files already use python for parsing
Tup's parsing model is different from make-like build systems. In make, parsing happens for every build, and is used to build an in-memory DAG that is then walked. Make's model forces an upper limit to how fast the build can execute, since the parsing and DAG-walking steps grow linearly with the size of the whole project. In contrast, tup only parses when necessary, not during every build. The results of parsing (essentially, the commands to execute) are stored in an on-disk DAG structure. Only the parts of the DAG that are relevant to the current build are loaded in memory. For example, if a single Tupfile in a large project changes, tup will only re-parse that single Tupfile, and update the on-disk DAG. Since configure runs outside of tup, this resulted in the following build flow:
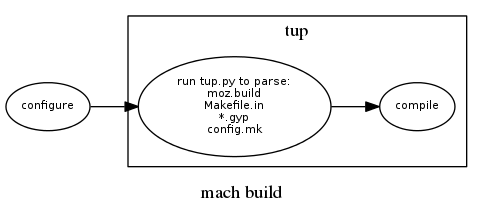
For projects that use Tupfiles or the built-in Lua scripts directly, this model works great. However, for the external python script used here, we run into some problems. First, because each directory is parsed independently, tup is creating a new python process to parse each directory. For incremental builds this usually isn't too cumbersome, especially for the typical case where no moz.build/Makefiles have changed (such as when you are just modifying .cpp/.h files, for example). Unfortunately, when changing the build configuration (like the tup.py script), the re-parse times are really bad. The reason for this seems to be largely due to python's slow 'import' statement. For example, just doing 'import pymake.parser', which we need to parse config.mk (even for directories that only have a moz.build file), is 36ms. Multiplied by ~1200 directories and we get 43 seconds, and we haven't even done anything yet! This would only get worse on Windows, where process creation time itself is horrible.
Now you're probably thinking "don't create a new python process for each directory and all your problems are solved!" While that would help the issues here, the reason that isn't so simple is because when tup parses a Tupfile, or runs a python script to parse moz.build/Makefiles, it is watching the file accesses for dependencies. These file accesses let tup know when it needs to re-parse a particular directory. In other words, if we're going to load all of the python files up front, then parse all of the moz.build/Makefiles, it becomes much harder to see what the directory-level dependencies are without injecting too much domain-specific knowledge into tup. You can see an example of this parser dependency graph below.
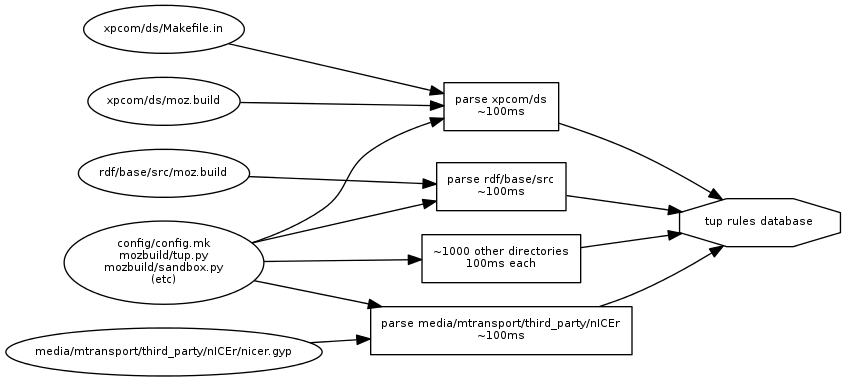
In this example, if we were to modify xpcom/ds/moz.build and then run tup, only the xpcom/ds directory would be re-parsed, taking about 100ms. However, if we were to modify any of the core build files (like tup.py, or any of the included mozbuild python files), each directory would be parsed independently. It might be possible to improve this situation in tup, but I think that would be a longer-term prospect. Coupled with the additional complication that this feature doesn't work in Windows yet, it's time to take a look at the picture if we just generated all regular Tupfiles up front before tup even runs.
Generating all Tupfiles up front
Instead of using tup to manage parsing directly, we can use an approach much more similar to the current mozbuild/make system and generate the native build files. This will have the following flow:
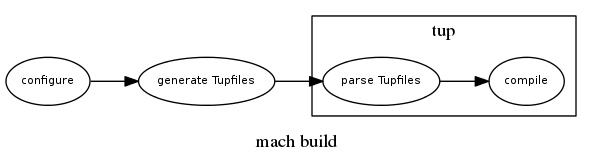
In this setup, mach is responsible for determining when to run configure and when to re-generate the Tupfiles. The Tupfile generation is similar to the current backend.mk generation, with the additional wrinkle that some of the data that we need is still in Makefile.in's, config.mk, and .gyp files, so it can't be done purely using mozbuild. Fortunately, we already have the tup.py script that can handle all of that - it's just a matter of hooking it into mach to run it in a loop instead of having tup run it for each individual directory. The Tupfile generation dependency graph will now look like so:
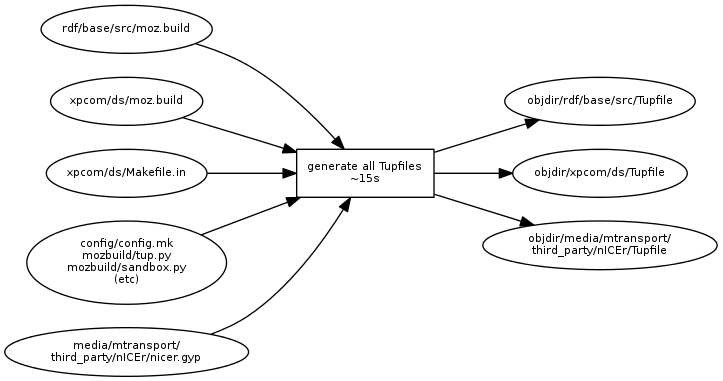
The Tupfile generation step itself currently takes about 15s. This is still much longer than I would hope, but I think much of this time is due to using the pymake parser to parse Makefiles. As we remove more Makefile.ins and eventually convert config.mk to python, I think this time will go down. Mach will only run this 15s process when any of the build configuration files on the left have changed. Otherwise, we only pay the smaller penalty of having to stat those files. Tup will then parse any Tupfiles that have changed - if all Tupfiles have changed, it's only about 2.6s of parsing. Most individual Tupfiles parse anywhere from 0-5ms, though a few outliers take 100-200ms (these appear to be directories that have lots of source files and use VPATH, which forces tup to do lots of dependency management. Once I finally finish getting rid of VPATH, those will hopefully drop too :). Of course, if only one or two Tupfiles have changed, then tup will just parse those in a few ms. Finally, tup can construct the partial DAG and begin build processes.
The downside to this approach is that if any of the build configuration files change, we have to re-run the full backend generation step at a penalty of 15s. In comparison, with tup managing parsing directly, we would be able to change a moz.build file and re-parse it in 100ms. However, this approach wins out in the full parsing case by a fair margin, and also makes a Windows tup build much more viable. Here's a brief summary of parse times in various scenarios:
| No build config changes | Change a single moz.build file | Initial parsing / Change all build files | |
| Tup managed with tup.py | 0s | ~100ms | 1m17s |
| Mach generated Tupfiles up-front | * | 15s | 17s |
| Idealized tup managed with internal parser ** | 0s | ~5ms | ~4s |
* I haven't implemented this in the Tupfile generation yet, so I don't know how much time it will take mach to stat all the files needed for this step. It should be small.
** Assuming tup could read the build configuration directly in a native Tupfile format or with a Lua script, this is what we could expect. Unfortunately, we don't have the ability to do this with the existing build configuration without writing lots of messy Lua code.
The future: Integrating a tup backend into m-c
As we look to include a tup backend in the mozilla-central tree, we have to decide on an approach. Here's a summary of the above analysis:
Tup-managed python script
- pro: Tup knows the parser dependencies, so it can re-parse only a single directory quickly when making a change to a moz.build file.
- pro: Since parser-level dependencies are tracked automatically, we don't have to worry about missing a dependency and breaking the build.
- con: Python's slow startup and import times negatively impact full re-parsings, so editing the build backend becomes cumbersome at over 1m turn-around times.
- con: Tup's run-script feature is not yet supported on Windows.
Mach-managed Tupfile generator
- pro: Full generation and re-parsing is much quicker (15s for mach + 2.6s for tup instead of over a minute)
- pro: It should be much easier to get this working on Windows as well as Linux/OSX
- con: Single moz.build change results in a full re-parsing, so we eat the full 17-18s when adding a new .cpp file to moz.build, for example.
- con: Python/mach do not have automatic dependency detection, so we have to be very careful about how we implement the Tupfile generator to properly track all file dependencies. If a dependency is missed, this can result in broken builds.
Although it is a difficult decision, I think for now it makes the most sense to go for the mach-managed Tupfile generator initially. Since the build configuration is a mix of so many different file types, there isn't a particularly easy way to have tup parse it natively. This does add some risk, since we have more of the build system outside of tup in manually-managed dependency land, but that is the price we pay. In the future as the build configuration becomes more unified (ideally, all specified in moz.build), we can look into parsing it natively with tup. At that point, we will gain the benefits of tup's dependency tracking for re-parsing moz.build files, and faster parsing overall.
comments powered by DisqusAbout
![]() Hello, you've reached Mike Shal's blog. I may have some info on build systems, Linux, and/or life at Mozilla. Hopefully you will find some of it useful!
Hello, you've reached Mike Shal's blog. I may have some info on build systems, Linux, and/or life at Mozilla. Hopefully you will find some of it useful!
Categories
Archive
Links
Quotes
We've been going about this all wrong. I blame myself.
- Sandlot